Offline Reinforcement Learning with Universal Horizon Models
Abstract
Model-based reinforcement learning (RL) offers a compelling approach to offline RL by enabling value learning on imagined on-policy trajectories. However, it often suffers from compounding errors due to repeated model inference on self-generated states. While geometric horizon models (GHM) alleviate this issue through direct prediction over a discounted infinite-horizon future, they remain challenged in accurately modeling distant future states. To this end, we introduce universal horizon models (UHM), a generalization of GHM that directly predicts future states under arbitrary horizons. Leveraging this flexibility, we propose a scalable value learning method that employs a winsorized horizon distribution to stabilize training by capping excessively large horizons. Experimental results on 100 challenging OGBench tasks demonstrate that the proposed method outperforms competitive baselines, particularly on tasks with highly sub-optimal datasets and those requiring long-horizon reasoning.
Universal Horizon Models
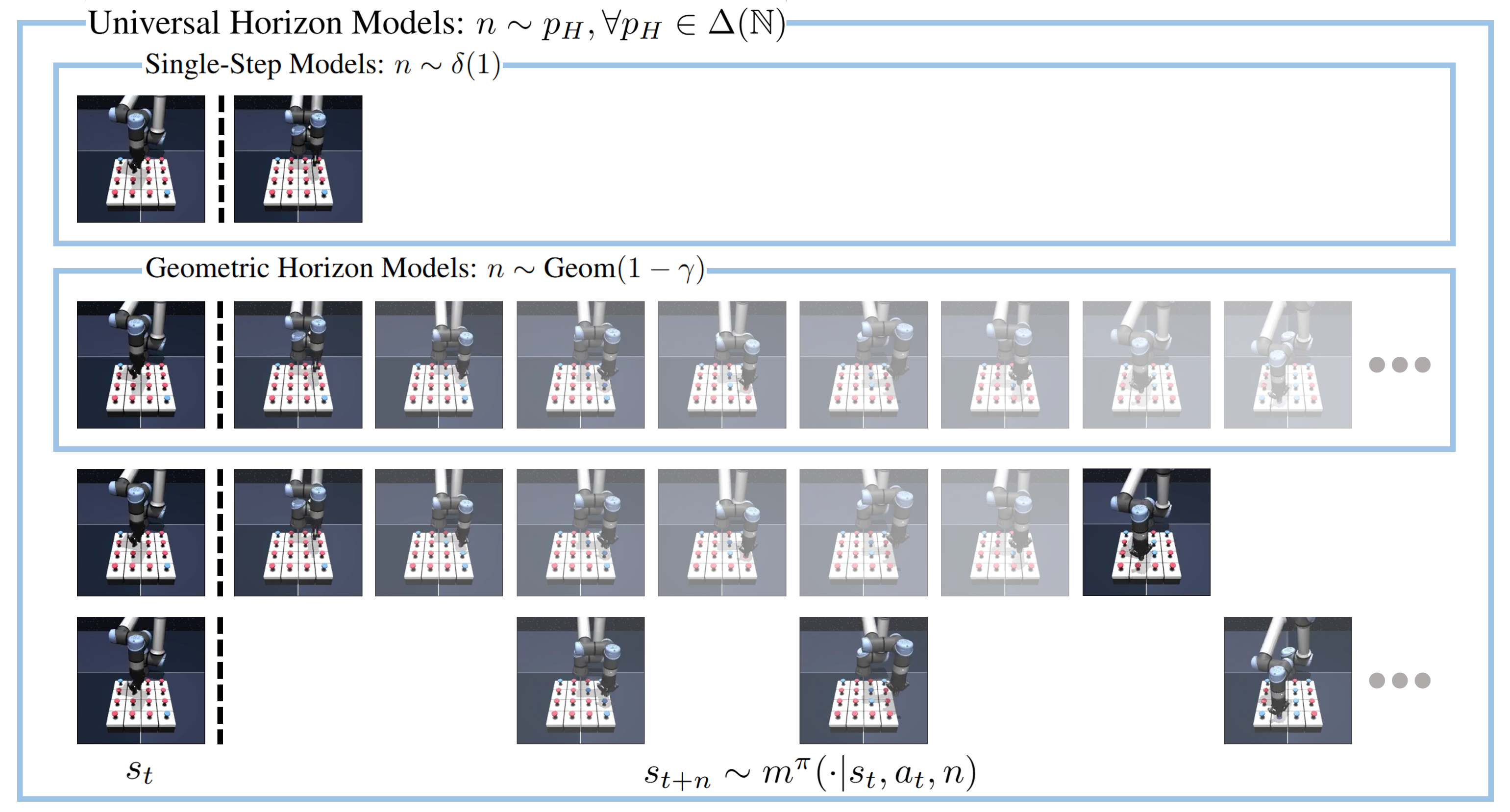
Universal horizon model (UHM) is a future predictive model that directly samples states from the \(n\)-step future state distribution of the policy for any given horizon \(n\). Since it allows \(n\) to be sampled from arbitrary distributions, UHM can be seen as a general framework that includes single-step models and geometric horizon models. UHM can be learned from off-policy transitions via bootstrapping analogous to the learning objective of geometric horizon models:
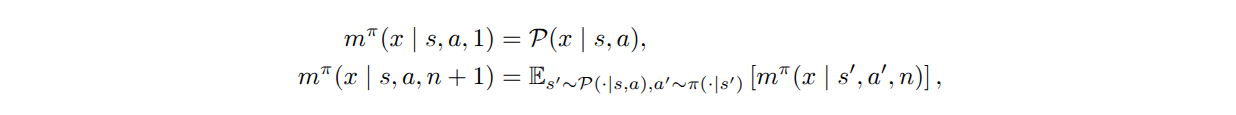
We follow temporal difference flow to train the flow network for generative modeling.
Value Learning with UHM
Based on the flexibility of UHM to represent and sample from arbitrary future distributions, we propose a generalized temporal difference learning framework.
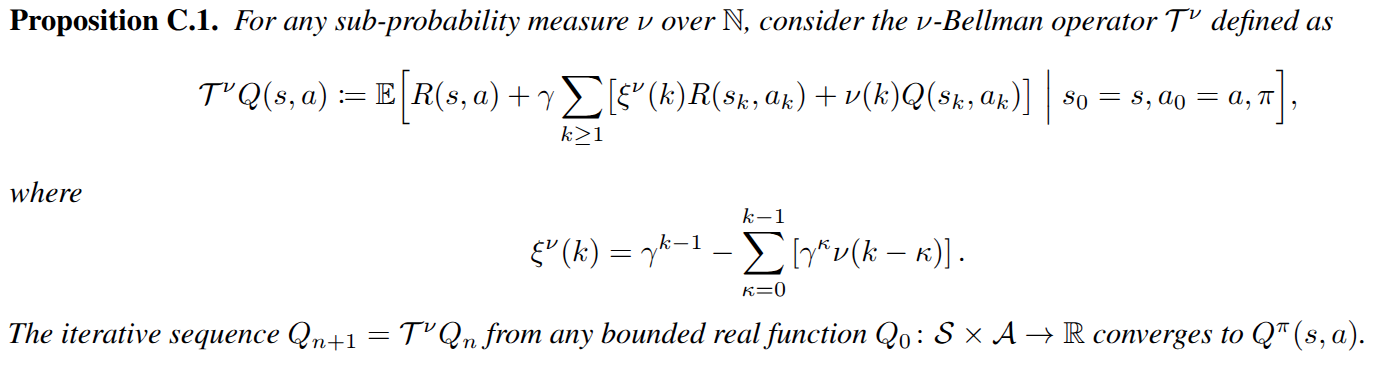
It recovers standard critic updates as special cases: choosing \(\nu(k)=\gamma^{n-1}\mathbf{1}[k=n]\) yields \(n\)-step TD, while choosing \(\nu(k)=(1-\lambda)(\lambda\gamma)^{k-1}\) represents TD(\(\lambda\)). UHM allows one-sample estimation of the \(\nu\)-Bellman backup target \(\mathcal{T}^\nu Q(s,a)\) for any sub-probability measure \(\nu\).

Among many possible choices of \(\nu\), we present a value learning method using the winsorized geometric measure.
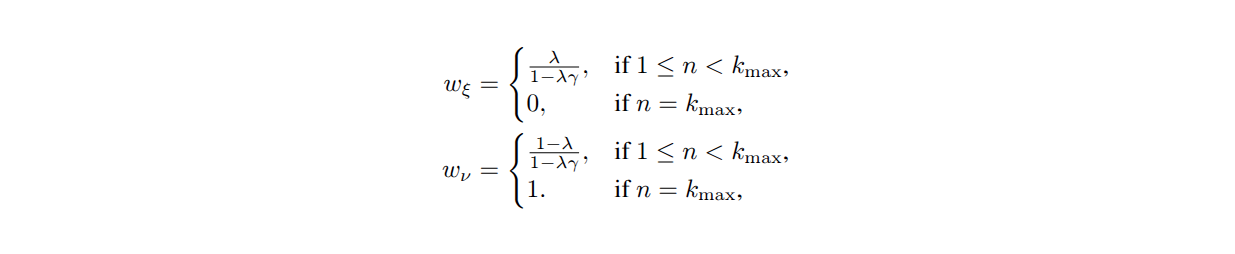
It stabilizes the learning process of model and value by capping excessively large horizons.
Experiments
Performance
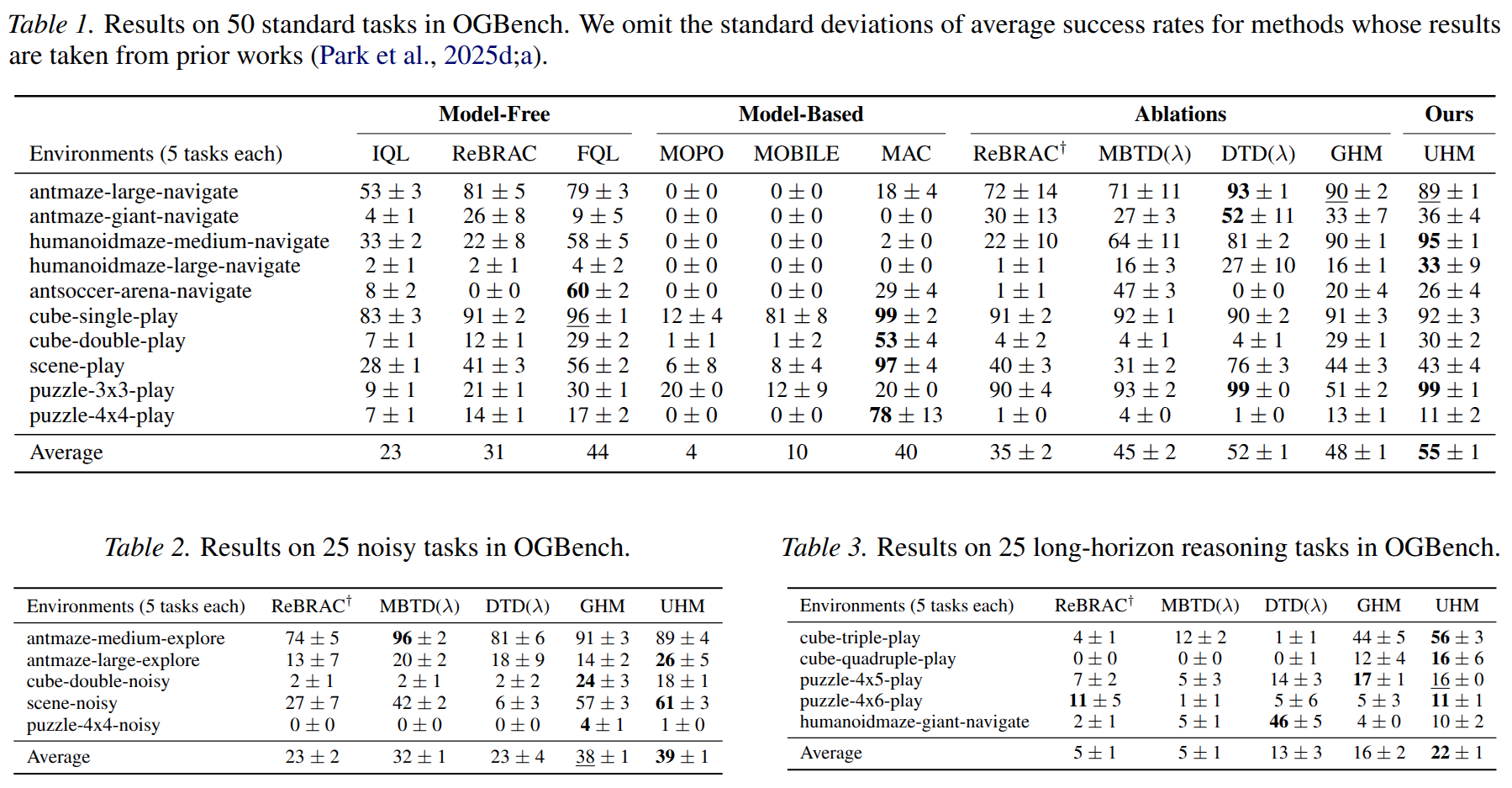
Our experimental results reveal three key findings. First, horizon reduction plays a crucial role in effective value learning. Second, model-based value expansion without repeated inference scales well to noisy tasks and long-horizon reasoning tasks. Finally, the proposed method shows competitive performance across the task categories we consider, with a 14\% higher average success rate than the second-best method.
Wall-Clock Time Comparison
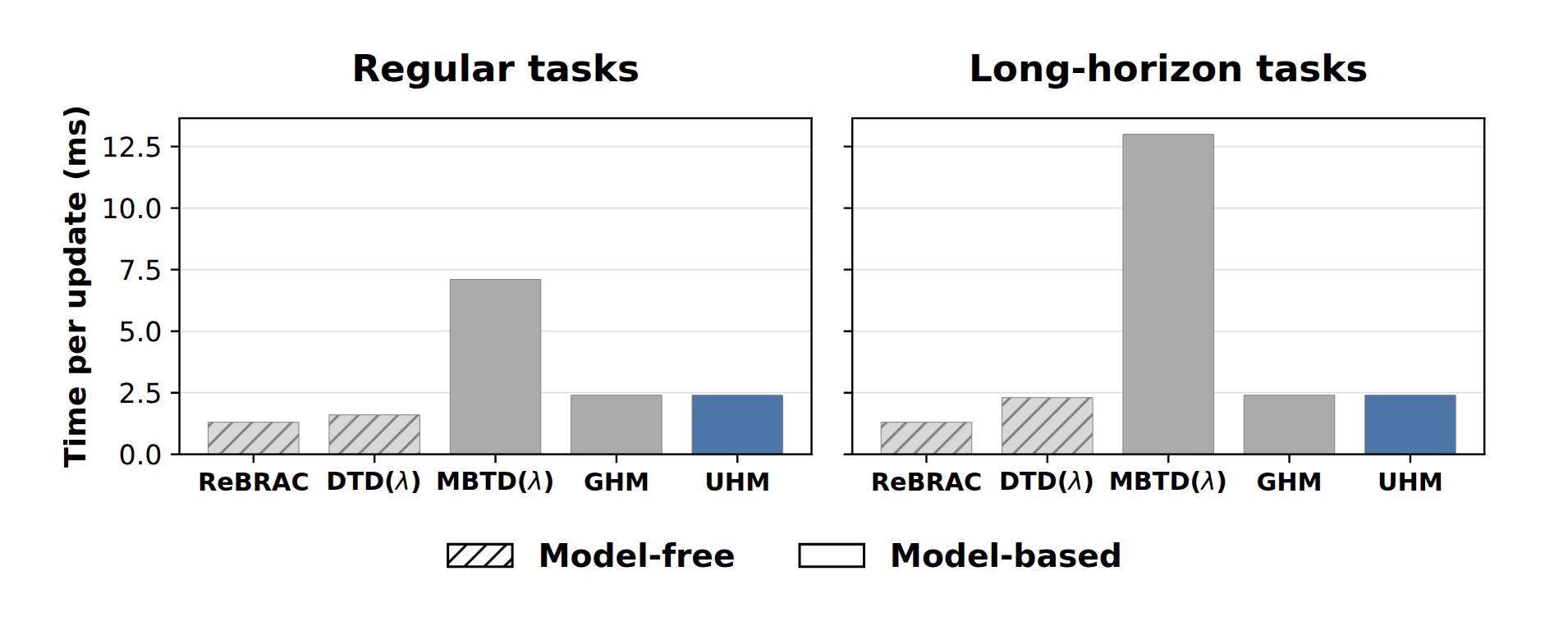
UHM (and GHM) significantly reduce the computational overhead of model-based approaches by directly predicting future states.
BibTeX
@inproceedings{
chung2026uhm,
title={Offline Reinforcement Learning with universal Horizon Models},
author={Hojun Chung, Junseo Lee, Songhwai Oh},
booktitle={Proceedings of the International Conference on Machine Learning},
year={2026},
}